
Hier j'étais en train d'essayer de filtrer un lexique contenant des formes infléchies au féminin et au masculin et je me suis rendu compte de quelque chose de marrant.
J'avais commencé à écrire un toot mais je me suis rendu compte qu'il y avait bieeeen trop de choses à dire et quand j'ai passé les 2000 caractères je me suis dit qu'il était plus raisonable d'en faire une note de blog. En plus l'avantage c'est que cet article pourra un peu servir d'introduction à cet autre que je vous promets d'écrire depuis un certain temps pour essayer d'expliquer ce que je fais comme travail.
## Quelques notions de base de linguistique de corpus
Vous connaissez sans doute la linguistique qui étudie le fonctionnement des langues, vous avez sans doute entendu parler de Traitement Automatique des Langues, ce rejeton de l'informatique qui prétend analyser le langage naturel comme les langages informatiques. La linguistique de corpus est quelque part entre les deux (bon, d'accord, le TAL est déjà un intermédiaire entre informatique et linguistique, on va dire que la linguistique de corpus en est un autre qui penche un peu plus sur la linguistique — c'est légitime, la moitié des TAListes sont des informaticiens qui pensent qu'il n'y a pas besoin de connaissances linguistiques pour s'attaquer aux langues humaines).
Bref, on utilise des machines, on traite d'assez gros volumes de données, mais ça se passe en laboratoire de Sciences Humaines et Sociales. La linguistique de corpus fournit aux linguistes des outils pour explorer des corpus constitués de grandes quantités de texte. Cela permet d'avoir accès véritablement à un «état» de la langue, et pas d'étudier seulement le style d'un ou deux auteur·rice dans un ou deux livres. Pour ce faire, on interroge le corpus au moyen de requêtes qui permettent de voir par exemple quelle préposition est utilisée préférentiellement avec quel verbe, ou d'expliquer dans quel contexte on préfèrera tel mot plutôt que tel autre alors que tout le monde s'accorde à les trouver plus ou moins synonyme.
Et pour faire ça, on doit «préparer» les textes. Il n'est en effet pas envisageable d'utiliser des expressions régulières pour chercher des motifs de caractères dans le texte : les linguistes s'intéressent à des choses plus abstraites comme par exemple la classe grammaticale des mots (dans le jargon on utilise l'acronyme anglais, POS pour «*Part Of Speech*», qu'on retraduit des fois pour parler de «partie de discours»).
## Un lemme, c'est quoi ?
Dans une langue qui a des inflexions, c'est à dire dont les mots vont prendre différentes formes en fonction du contexte (quelle est sa fonction dans la phrase, quel genre on lui associe, est-ce qu'il y en a un ou plusieurs, quand est-ce que ça s'est passé, etc.), c'est à dire à ma connaissance toutes les langues, d'une façon ou d'une autre, au moins sur certains mots, il n'est pas pratique de chercher des mots avec des expressions régulières.
D'accord, ça marche pour des mots avec très peu d'inflexions. Si je cherche dans mon texte, toutes les occurrences du mot «arbre», ça va, il n'existe qu'au singulier et au pluriel.
<pre class="example">
arbres?
</pre>
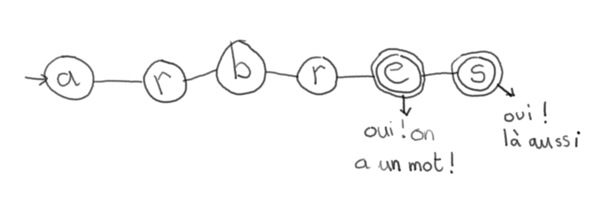
Ça va, on s'en sort bien. Mais imaginons que je cherche le verbe «aller», quels que soit le temps et la personne à laquelle il est conjugé ?
<pre class="example">
(v(a(i?s)?|ont)|all(ons|ez))
</pre>
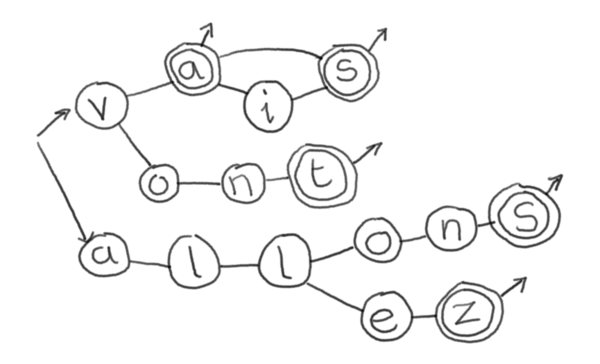
Vous avez vu la tête de ce machin ? Et là je n'ai pris en compte que le présent de l'indicatif. En plus, je le répète il est utile de croiser les informations parce qu'en faisant ça nous n'aurions accès qu'à la forme que prend le mot, et pas du tout à sa nature grammaticale. C'était très impressionnant de montrer «aller» qui est gravement irrégulier mais même avec un verbe comme «marcher», une expression régulière ne fera pas la distinction entre le participe passé du verbe, «marché», et ce qui mentionnerait un «marché aux puces».
Donc, quand on analyse le texte, on essaye de trouver quelle est la classe grammaticale des mots, et normalement si on la trouve on a aussi identifié «le» mot dont dérive cette forme, c'est à dire qu'assez naturellement on a l'idée d'une forme «normale» de ce mot à partir desquelles les autres sont infléchies. Vous n'allez pas me dire que le mot «arbres» est un mot différents de «arbre». Vous sentez bien qu'il y a en dessous «le» mot «arbre», et qu'on peut le rencontrer au singulier ou au pluriel. Dans ce cas on associerait à la forme rencontrée «arbres» l'information qu'il s'agit d'un nom commun et que la forme «normale» du mot est «arbre».
Il y a sans doute d'autres informations très pertinentes à associer aux mots mais dans les projets sur lesquels je travaille en ce moment nous utilisons systématiquement et exclusivement la forme du mot, sa POS, et cette forme normalisée, le «lemme».
| forme | POS | lemme |
|--------|-----|----------
| arbres | Nc | ARBRE |
| vas | V | ALLER |
| marché | V | MARCHER |
| marché | N | MARCHÉ |
## Et alors, notre lexique ?
Dans le lexique qui m'occupe, il y a des entrées «dupliquées», c'est à dire mal normalisées pour moi. Par convention, nous utilisons la forme au masculin pour le lemme, c'est à dire que nous considérons que le mot «radieuse» et la forme au féminin de l'adjectif dont le lemme serait «RADIEUX». Or, nous avons pour certains mots plusieurs entrées, une avec la forme masculine comme lemme mais aussi une avec la forme féminine.
Oui, c'est discutable en soi de pourquoi la forme masculine serait la forme par défaut, mais c'est pas mon sujet icitte et d'ailleurs Marina Yaguelo analyse fort-bien cela dans son livre «Les mots et les femmes». Elle y explique qu'en français à l'écrit la forme «naturelle» a l'air d'être le masculin, et qu'on obtient le féminin en ajoutant des lettres (souvent un 'e' quand même, après un éventuel redoublement de consomne).
<pre class="example">
permis -> permise
</pre>
À l'oral la perspective est inversée : un grand nombre de mots masculins, comme ici «permis», contiennent une consomne finale muette, et le mot tel qu'il est entendu au masculin ne permet pas d'expliquer quelle consomne apparaît «magiquement» au féminin si bien qu'il est plus naturel de considérer à l'oral la forme féminine comme forme par défaut, et d'expliquer le masculin comme étant une forme tronquée du mot complet, dont la forme de base serait féminine.
<pre class="example">
\pɛʁ.miz\ -> \pɛʁ.mi\
</pre>
Mais comme je l'ai dit ce n'est pas mon propos. Ce qui compte pour un lemme, c'est qu'il soit une forme «normale», commune aux différentes inflexions d'un mot, ce qui permet ensuite de chercher dans un corpus, «le verbe PERDRE, quelle que soit sa forme, suivi d'un nom commun», sans s'embarquer dans des regexps incroyables. On pourrait choisir la forme tronquée avant toute terminaison «VOYAG» plutôt que «VOYAGEUR», on pourrait choisir la forme en écriture inclusive. Ce qui aurait l'immense avantage de faciliter la génération de texte à partir du même lexique puisque le lemme contiendrait alors toute l'information nécessaire pour générer toutes les formes possibles au masculin comme au féminin alors qu'il faut connaître nous seulement des règles de morphologie française mais aussi des règles spécifiques à chaque mot pour savoir que si le lemme est «VOYAGEUR», la forme féminine sera «voyageuse» et pas «voyagine» (ce serait méconnaître les règles de morphologie) ni «voyagrice» (ce qui serait ignorer le modèle particulier que suit le mot «voyageur», pour des raisons morphologiques, mais qui semblerait possible en considérant des exemples comme la paire masculin/féminin «inspecteur/inspectrice»).
En l'état, des fausses ambiguïtés apparaissent car par exemple le lexique contient
| forme | POS | lemme |
|------------|-----|------------|
| religieuse | Nc | RELIGIEUX |
| religieuse | Nc | RELIGIEUSE |
donc en tombant sur une occurrence du mot «religieuse», l'étiqueteur se dit : «aïe, c'est un cas ambigü, ça pourrait être le mot "RELIGIEUX", mais en fait ça pourrait tout aussi bien être "RELIGIEUSE"». C'est n'importe quoi ! Vous vous souvenez ? C'était pour éviter ça avec les formes qu'on avait choisi d'avoir des lemmes !
Il y a en français plein de paires de terminaisons masculin/féminin :
- **e/esse** : prêtre/prêtresse, bougre/bougresse, âne/ânesse, maire/mairesse…
- **eux/euse** : religieux/religieuse, gueux/gueuse
- **eur/rice** : lecteur/lectrice, instituteur/institutrice, acteur/actrice…
- **eur/euse** : coureur/coureuse, danseur/danseuse, fauteur/fauteuse
Il se trouve que dans le projet la plupart de ces cas étaient déjà traités, mais à un endroit et d'une manière peu efficace. De plus, la paire «eur/euse» n'avait pas été faite et je m'interrogeais donc sur la possibilité de couper le mal à la racine en retirant directement les entrées avec le lemme «au féminin» comme
| forme | POS | lemme |
|----------|-----|-----------|
| voyageur | Nc | VOYAGEUSE |
du lexique et je voulais tester cette idée pour cette nouvelle paire. Mais attention ! Il ne s'agit de faire ça que pour les mots pour lesquels il existe une ligne avec la même forme et la même POS mais le lemme au masculin, sans quoi on risque de perdre du vocabulaire. J'ai donc généré un filtre des lignes à exclure à partir des lignes dont le lemme est au masculin (vous me suivez ? mais si, c'est logique, on retire le féminin mais que là où il y a du masculin donc on cherche les formes au masculin).
```bash
sed -n 's|.*euse.*\t[A-Z][a-z]*\t\(.*\)EU[RX]$|\1EUSE|p' lexicon.tmp | sort -u > blacklist.txt
```
Et bien sûr par curiosité mais aussi pour m'assurer que ça marche bien, je regarde ce qu'il me reste comme entrée dont le lemme finit par «EUSE» en excluant ces lignes du lexique.
```bash
grep -vf blacklist.txt lexicon.tmp | sed -n 's|.*euse\tNc\t\(.*EUSE\)$|\1|p' | sort -u | less
```
J'obtiens une liste avec encore pas mal de noms communs renvoyant à des activités : «acheveuse», «attrapeuse», «chroniqueuse», etc. mais pour lesquels il existe une forme masculine. J'ai cherché dans le lexique, il se trouve que ces formes ont été mal renseignées, et qu'au lieu d'avoir une ambiguïté causée par deux entrées, une avec le lemme au masculin et une avec le lemme au féminin, elle n'en ont qu'une, pour le lemme au masculin… donc le système de traitement de trouvera jamais les «chausseuse» si on l'interroge sur le lemme «CHAUSSEUR».
Bon, décevant au niveau de la cohérence du lexique, mais regardons ce qu'il reste. Ce qu'il reste, c'est la plus formidable liste de noms de machines que j'avais jamais vue : «additioneuse», «asphalteuse», «badgeuse», «bétonneuse», «dénoyauteuse»… et bien sûr, la «tronçonneuse». Il semble que les noms communs n'existant en propre qu'au féminin avec la terminaison «-euse» en français soient… des noms de machine : )